FireSOM - prediction of behavior from acceleration data
Machine-learning assisted acceleration segmentation
When working with acceleration data manual annotation of large-scale data may be time-consuming or near-impossible.
Via Data > Acceleration > FireSOM Segmentation you can trigger Firetail’s automated segmentation algorithm FireSOM.
IMPORTANT: Firetail’s annotation features are activated when loading data via
Download Movebank by ID/Tag/Deployment. Your annotation is saved locally (on your machine) along with the downloaded data.
Introduction to FireSOM
In addition to GPS fixes modern animal tags can provide high-resolution acceleration data measuring relative movement changes with respect to gravity in multiple, typically three (XYZ), axes. Commonly, the data is recorded as bursts. In this context, a burst is a sequence of measurements that is consecutively recorded at a fixed frequency for a limited amount of time. The burst length can range from few seconds to several minutes depending on the research context or dynamic tag settings.
The FireSOM algorithm as implemented in Firetail is an assistive system designed to annotate burst data by clustering bursts into abstract categories based on their overall similarity.
Machine learning algorithms share the idea to estimate data similarity via encodings of user-selected features rather than by comparing raw data. In FireSOM, each burst is first encoded as a vector of features. For simplicity, the user can select feature groups rather than single features. Selecting a group would then append all induced features to the feature vector of each burst.
To cluster similar bursts, FireSOM employs a self-organizing map (SOM, also referred to as Kohonen map [1]). A SOM is a 2-dimensional grid of (weighted) nodes. Each node represents a potential cluster/category. Placing bursts on the map (referred to as training) adapts the map structure (the node weights) to the dataset.
After the training all recorded bursts are placed in the cluster that resembles its characteristic vector best. Bursts with similar features are located spatially close on the map or within the same node. They are assigned to the same category.
The initial result is an assignment of an abstract category to each burst. This can be visualized by annotation layers above the raw acceleration data (one layer per category). Abstract categories can then be analyzed in a GPS and sensor data context and assigned to known behavioral categories. By overlaying observation data or gold standards the validity of the predicted categories can be analyzed.
FireSOM can refine predicted categories via second layer predictions (re-train a category), merging of categories that are very similar and discard categories. This iterative refinement can be used to annotate complete datasets and also transfer results by using pre-trained models for the prediction of other tags, individuals or deployments.
FireSOM - Overview of the core algorithm steps
- calculate a set of user-selected features for each burst
- normalise (standardization) extracted features
- train the FireSOM (self-organizing map) using the bursts mapped into feature space
- assign each burst to a category
Video Tutorial
Here you can find a video tutorial on FireSOM, see below for more details
How to choose the map size?
The map size can be selected freely and must be adapted to the number of distinct behavioral categories. While more categories require more space on the map (more nodes), a large map requires more training data. Complex data patterns may require more nodes to reflect subtle changes in the data.
Start with as few as 9 nodes (a 3x3 map) and run FireSOM with basic statistic features enabled. This will likely separate active from inactive patterns. Some categories cover a too broad range of patterns (multiple behaviors). Move affected categories to a separate layer and use Annotations to Selections to refine these categories by restricting a second iteration of FireSOM on this selection.
Some datasets may require larger map sizes and more refinement steps. The model dimension determines the number of predicted categories. For a 4x5 sized map you’ll retrieve a maximum of 20 categories. Empty categories are deleted.
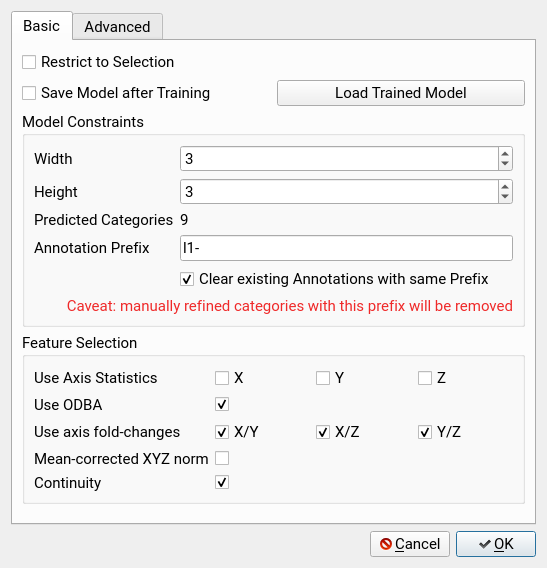
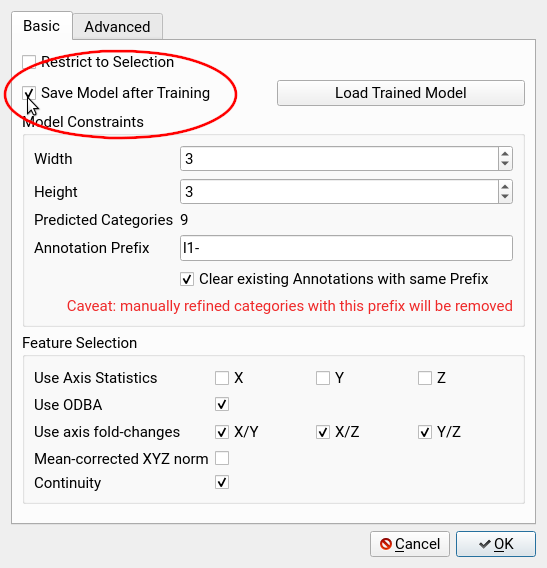
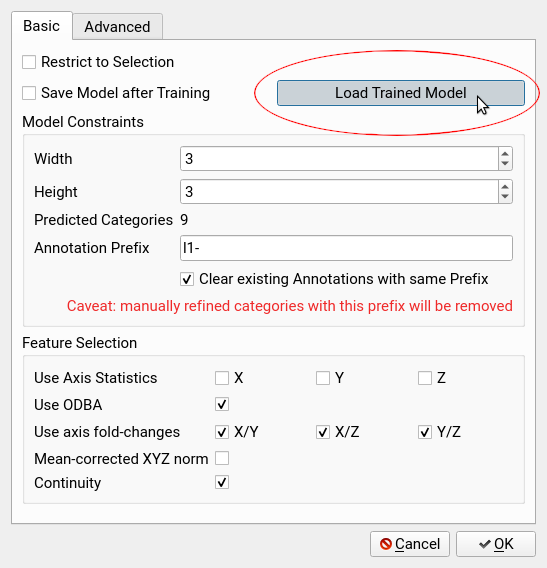
Model Constraints
Width: the number of horizontal nodes, we suggest to use at least 3 depending on the complexity of data patterns
Height: the number of vertical nodes, we suggest to use at least 3 depending on the complexity of data patterns
Annotation Prefix: Each predicted category will be prefixed with this string
Clear existing Annotations with the same Prefix: Any previous annotation with this prefix will be removed. Rename auto-predicted categories to avoid data loss.
Feature Groups
For simplicity, the user can select groups of features rather than single features. Selecting a group would then append all induced features to the feature vector of a burst. The following groups are available:
Axis Statistics: distribution statistics, each axis Basic features that encode per-axis statistics, in particular the maximum, minimum, median and 25%/75%-quantiles of a burst. We refer to this as canonical encoding. Specific axis may govern specific behavior (Y axis: upside down, X: forward, Z: shifting).
ODBA: overall dynamic body acceleration encoded as a feature, all axes The ODBA value with respect to the burst mean constitutes a single-value feature reflecting the energy usage of the burst.
axis fold-changes: distribution statistics for the log-2 fold-changes, pairwise axes The ‘axis fold-changes’ will compute the log-2 fold-changes among selected axes and then compute distribution statistics. Pairwise relations among axes may hint at complex movements.
mean-corrected norm: add the mean-corrected norm value for each burst The ‘mean corrected norm’ computes a normalized length for each recorded sample vector and computes canonical distribution statistics. The feature reflects an overall direction bias.
continuity: add a measure of sum of changes The absolute sum of changes that occur within a burst provides a single-valued feature reflecting the degree of movement in a burst. It resembles a non normalized flavor of ODBA.
Click OK to train a model and see your results as new layers in the acceleration window.
Inspecting the model
While it is easy to train a model in Firetail, there is no intrinsic way for Firetail to decide on model quality.
Inspecting a predicted model is crucial
Firetail provides you with a lot of context that makes it easier to interpret the predictions and would also allow to overlay annotations as gold standards, 3rd party predictions, or observational data. But also location data data and sensor data may hint to prediction quality.
Overall, the model is based on the similarity of two bursts in feature space, so similar patterns should be assigned to identical or nearby categories. Neighborhood is defined in a tabular row-column sense, i.e node (1,4) is a direct neighbor of (1,3), (1,5), (0,4) and so on.
Think of patterns in terms of activities like rest, running or feeding. The more categories you predict the more behavioural complexity can be detected. For increasingly many categories it may become necessary to join predictions via layers to group similar categories.
Start simple
Therefore, start by training a simple model with dimension 3 by 3 and few features. You can easily train a quick model as a preview or even experiment with how well a single feature works for discrimination of visual patterns or regions of known behaviour.
Increase complexity if required
An increasing number of features means there is more freedom to discriminate bursts. The result model will be harder to interpret though. Incrementally increase model complexity and add features when two regions you deem dissimilar are placed in the same category.
Refine using local models
If the data features local specificities it makes sense to run the segmentation on a selection.
Make sure that at least a few hundred bursts are selected to avoid a poorly fitted model.
In this context, the option Restrict to Selection must be enabled.
The algorithm will predict categories only for selected bursts. Choose a distinct model prefix to make sure to maintain both global and local predictions.
Refinement of specific categories
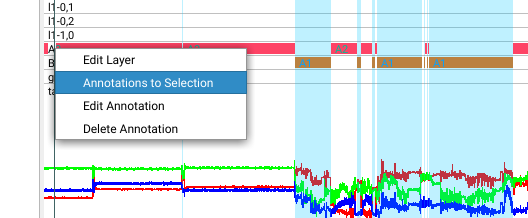
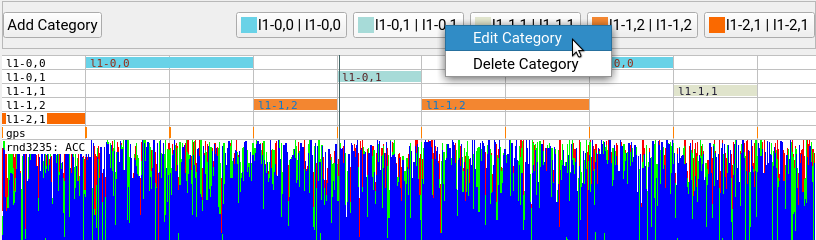
Right-clicking on an annotation layer allows you to select annotatated regions by choosing “Annotations to Selections”.
This leads to a powerful workflow:
- select regions that could not be segmented properly by the initial, coarse model
- make sure that the regions to be refined are selected
- re-run FireSOM using
Restrict to Selectionand a new model prefix - evaluate the local model via merge/delete semantics as discussed below
Assign, Rename and group
The machine-assigned group names cannot magically predict “running”, “feeding” or “flying”. Screen the predicted categories visually and in their best possible context to assign a category to a possibly preliminary behaviour. Repeated
- application of the segmentation
- changes in parameters and
- successive joining of categories into layers
- refinement of coarse categories
- deletion of superfluous categories
will lead to sensible annotations for a complete dataset.
Saving a model
You can save a trained model for later use on another dataset or selection. This provides a very powerful way to avoid the inclusion artifacts or to build more specific models. The core idea is to sort bursts into buckets defined in another context. Therefore, this strategy should work best on similar input data, although there is no technical constraint keeping the user from applying models cross-species or across tag-types.
A common use case is to save global and refined models for one dataset (see refinement) and then re-apply the models on another dataset.
An appropriate setup could also help to enforce consistency checks and enable in-depth validation.
The key steps are:
- check
Save Model after Training - set the required parameters and features
- press
OKto train the model - select a file to save the training state
A model is a json file that includes required map-weights, parameter settings and the selection of features. The application of this model on different data requires the same parameters and features.
Using a previously trained model
It is possible to use a trained model to predict other datasets from the associated acceleration data.
In principle, you can cross-apply any model to any target. As tags and individuals may be subject to certain biases the model transfer can also imply biased predictions. These biases can only be detected using extrinsic references, wherefore FireSOM cannot automatically compensate for these effects. Still, the transfer of predictions across tags with a sensible degree of similarity is a powerful concept.
To cross-apply a model to (unannotated) other datasets:
- load the model to be applied via
Load Trained Model - optional: choose a new prefix to avoid losing existing annotations
- note that the feature selection and most parameters will be deactivated
- press
OK
The (selected) bursts are then classified using the pre-defined model.
Saving layer assignments and renaming of categories
Starting from Firetail 10 it is possible to save the re-assignment of layers and any renaming of categories along with a FireSOM model:
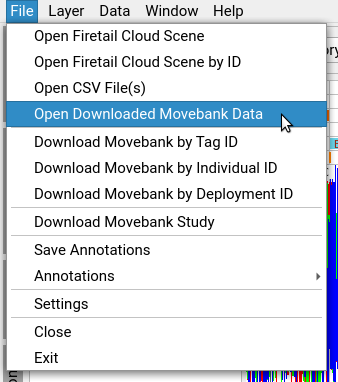
- open a Movebank project with associated ACC data, e.g. via
File > Open Previous Downloads
- use
Data > Acceleration > FireSOM Segmentation > Calculate ACC Segmentationto train a new model on the data
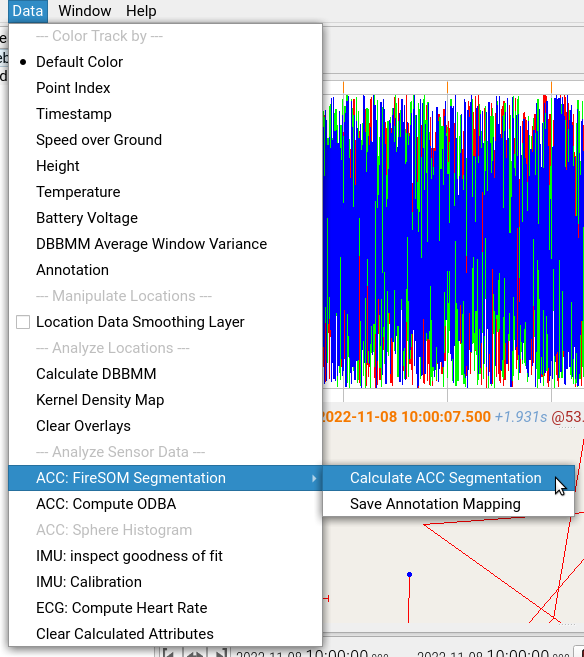
- check
Save Model after Trainingand pressOK
- edit predicted categories to new layers or rename them
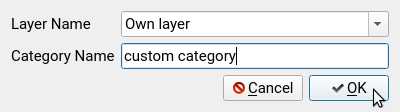
- save your edits via
Data > Acceleration > FireSOM Segmentation > Save Annotation Mapping
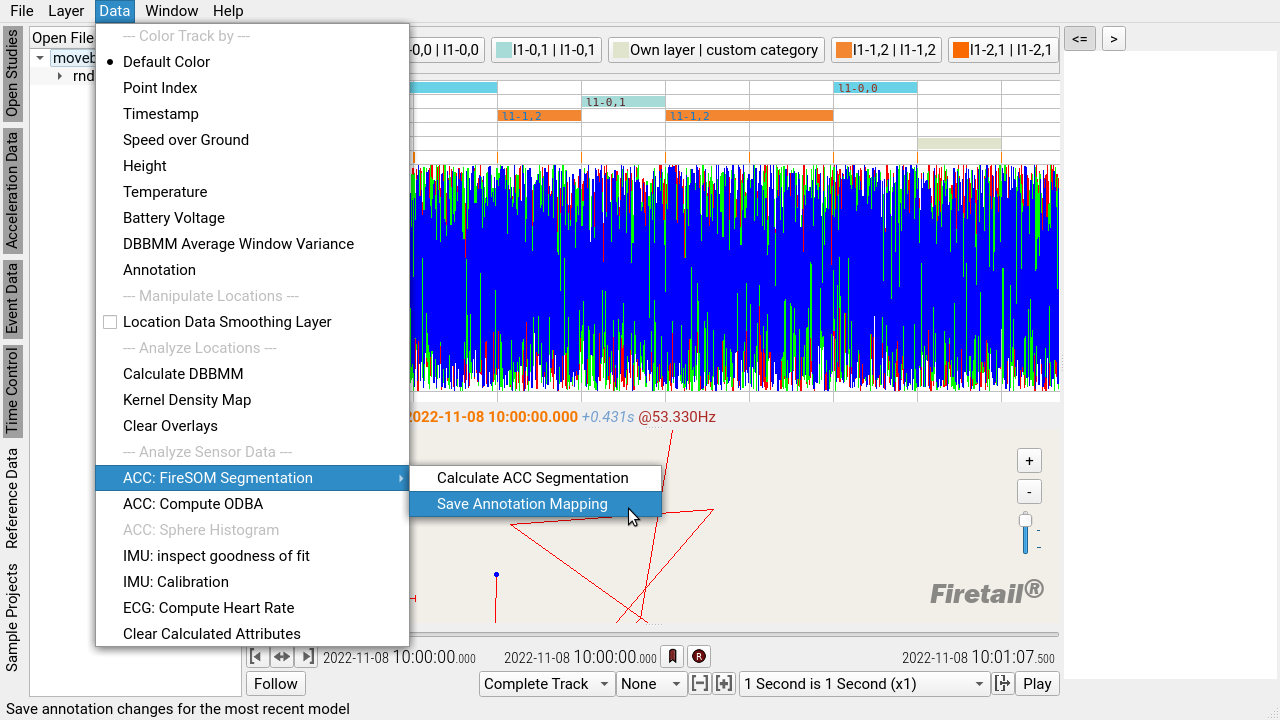
This will save all edits within the last predicted model. Repeat saving the annotation mapping whenever changes are made.
Note that this mechanism cannot be used across Firetail restarts as it requires an associated model, while set annotations are not bound to a single model or resource.
When using the saved model to predict another data set the modifications will be applied automatically. Firetail 12 will also include the type of data predicted (Acceleration/Gyroscopic/Activity) in its models as well as the layer name.
The layer name prefix is essential for the application of saved mappings. If the layer name (open the model ‘.json’ file using a text editor if you are unsure about the assigned prefix) is mismatched, Firetail cannot re-apply the category edits for a model.
External gold standards
The combination of selecting regions and manual editing can be extremely powerful. It can also lead to models that overfit to your data.
Typically, you should not expect that all patterns in your data can be explained from acceleration data alone. FireSOM will approximate a pattern-behavior relation, but cannot implicitly estimate its quality.
If you feel that a trained model would fail completely when applied to different tags or individuals the underlying model may be trained too specific to your training data. Therefore, despite Firetail can build very specific models on sub-selections it is important to use extrinsic observations to estimate the model accuracy.
BORIS video annotation
A potentially powerful source of external annotations are video annotations. Recording animals during their daily routines while simultaneously recording accelerometer data can provide orthogonal perspectives to behavior. Also, video annotations may serve as a sensible gold standard for FireSOM predictions.
Apart from serving as a gold standard, the video annotation data is useful to map categories to behavior by identifying observed behavior that overlaps well with the predicted categories.
There are currently two ways to load external gold standards in Firetail and inspect both predicted and external categories simultaneously:
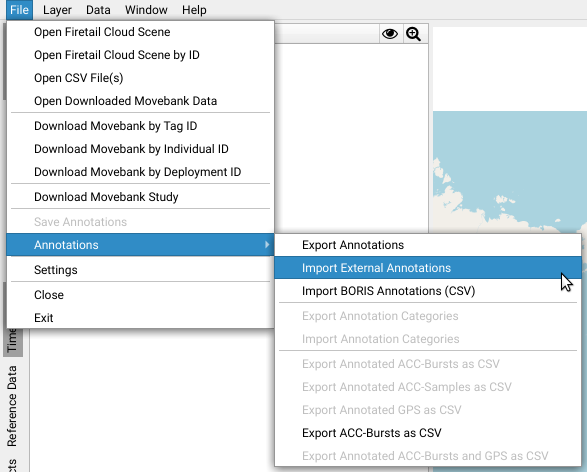
- convert external annotations to the Firetail annotation exchange format and load it via
File > Annotations > Import External Annoationsor - export
tabular eventannotation data from BORIS (BORIS video annoation). Import the resultingcsvviaFile > Annotations > Import BORIS Annotations
See External Annotation Sources for a detailed discussion on working with video annotation data.
References
[1] Kohonen, Teuvo (1982). “Self-Organized Formation of Topologically Correct Feature Maps”. Biological Cybernetics. 43 (1): 59–69. doi:10.1007/bf00337288. S2CID 206775459