Annotation of multi-axis sensor and acceleration data
Modern collars and tags record a variety of high resolution sensor data. Annotating the data in terms of ethograms or behavioral categories has a wide range of applications in movement ecology and conservation.
Firetail features a powerful annotation module that enables manual and automated (see FireSOM) data annotation for multiple sources of data:
(1) acceleration data (2) activity data (3) gyroscopic data
As of Firetail 12, it is possible to annotate tags, individual and deployments from Movebank as well as locally available data.
Acceleration data
Acceleration sensor data is among the most widely available data types. Tags will typically record data either continuously, or in short bursts.
For Firetail, a burst represents the shortest unit that can be annotated. Therefore, Firetail provides means (File > Settings > Import) to split continuous data into bursts.
Use File > Annotations > Enable Annotations to show the annotation panel above the acceleration burst viewport.
Custom acceleration data upload to Movebank
Finding the correct settings to upload acceleration data to your Movebank project for seamless usage in Firetail can be a bit tricky and specific to your tag vendor.
The following section provides some general guidelines to upload acceleration data as accessory data at the example of an Ornitela csv. These steps resemble the general workflow for manual uploads.
From the Ornitela/Vendor portal:
- Login to your vendor’s portal and download individual sensor data as CSV data (
Ornitela Sensors_V2 CSV) - Login intoOpen your Movebank project and upload data by “Other accessory data collected by your tags”
Add the following columns
| Column names | Movebank Attribute | Comments |
|---|---|---|
| device_id | Tag Id (if more than one individual) | Leave Animal Id blank (existing animal name different than tag ID) |
| device_id | All rows belong to same Animal/Tag (select tag and animal) | |
| datatype | Sensor Type (Acceleration) | For Ornitela, map each of the following to acceleration: SEN_ACC_20Hz_Start, SEN_ACC_20Hz, SEN_ACC_20Hz_End, SEN_ACC_20Hz_ENDINT |
| UTC_timestamp | Timestamp (UTC +0) (yyyy-MM-dd HH:mm:ss.SSS) | Different than UTC_datetime (do not map) |
| acc_x | Acceleration Raw X | Conversion factor 1 |
| acc_y | Acceleration Raw Y | Conversion factor 1 |
| acc_z | Acceleration Raw Z | Conversion factor 1 |
- Open Firetail and download (or update) the deployment/tag/individual data. The accessory file will be saved to
movebank_downloads/<yourstudy_id>
Activity data
Activity data represents a summarized form of acceleration data and typically feature a reduced sensor frequency like 1Hz or less.
Note that aggregating these data as bursts using Firetail’s burst detection and splitting mechanisms will create longer bursts for the same amount of samples.
Annotation entities
Sensor Data can be annotated for:
- Movebank individual
- *Movebank tag
- Movebank deployment
- Local data, individual
- Local data, tag
- Local data, deployment
Important: data annotation works for one instance (grouping: individual, tag, deployment)
Core concepts
Firetail features layers as highest level of organisation.
A layer can hold arbitrary many categories.
Each category resides on one specific layer.
A burst (see also Burst vs. continuous recording) can be assigned to
one or more categories.
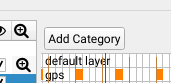
Add new categories
To add a new category press Add Category above the acceleration window
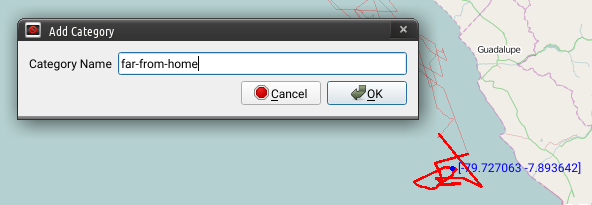
Assign a name to the category
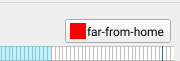
The category will show up above the acceleration window
Save and Load Annotation Categories
Annotation is usually a process done as a team to ensure consistency to have the possibility to check for inter-annotator agreements. Sharing a common set of annotation categories is crucial.
With Firetail you can save the current set of categories and layers.
File > Annotations > Export Annotation Categories.
The resulting file can be shared and re-imported. To add the categories to your current project, use File > Annotations > Import Annotation Categories.
Working with external annotations
Firetail provides an exchange format for annotations.
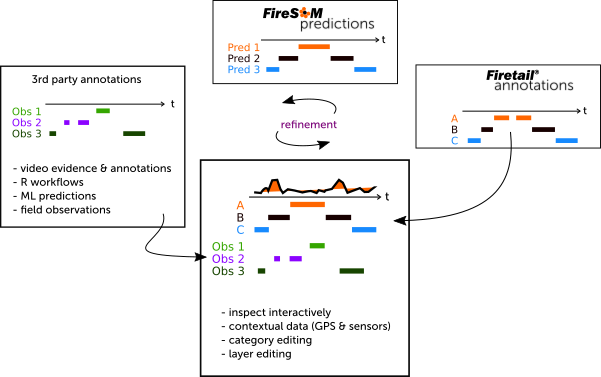
You can import multiple external annotation files. This allows you to
- overlay ground truth data alongside with predicted annotations
- interpret reference data in the context of FireSOM predictions
- compare multiple predictions
- merge annotations from distinct sources
and much more.
Export/Import annotations
Caveat: Export/Import must not be confused with
File > Save AnnotationsSaving causes the data to be saved along with your project. Export is designed to share annotations with peers or process external annotation resources.
To export annotations from Firetail use File > Annotations > Export Annotations.
Select a filename of your choice and confirm your selection.
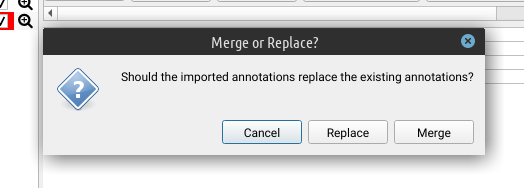
To import annotations use File > Annotations > Import External Annotations.
Choose a csv annotation file and confirm your selection.
You will be asked about the procedure.
- Replace: existing annotation layers will be replaced by the annotation file
- Merge: layers and categories are merged with the existing annotation
The Firetail annotation exchange format
The current exchange format is contains comma-separated values as follows. The following sample shows the required header columns (UTF8 csv) and few sample categories across several layers
category, layer, start-timestamp, end-timestamp
"in", "default layer", 2012-06-01 08:20:00.000, 2012-06-03 21:21:10.000
"out", "default layer", 2012-06-15 16:22:03.000, 2012-06-15 23:27:30.000
"foo", "default layer", 2012-06-16 00:50:01.000, 2012-06-18 22:02:02.000
"bar", "flying", 2012-06-16 23:51:01.000, 2012-06-18 23:55:02.000
"bar", "flying", 2012-06-16 23:56:01.000, 2012-06-18 23:57:02.000
Each line one annotation category mapped onto a layer. category and layer are
string types, whereas the timestamp should be an ISO timestamp with 3 ms digits.
If external resources do not feature a layer concept, the “default layer” can be assigned.
Firetail will gradually be extended with specific converters/import filters for external annotation formats. If you feel that a format is sufficiently important for many users please don’t hesitate to contact us!
Currently, the tag/individual/deployment information is not saved along with the data. The reason is that external tools are not aware of movebank conventions while grouping (layering) and category assignments with a distinct start and end are generic concepts. Exported data must not be mistaken for a complete snapshot including all required meta-information.
Make sure to include sufficient information in your filename structure to properly map your data to the respective tags or individuals.
Assign a category to a region
Once you have defined categories, you can use the selection mechanism described here to define regions that you’d like to annotate with one of your categories.
- Select a region within the bursts or the map
- Press on the category you want to assign this region to
The newly assigned category will be shown in a row/layer above the acceleration data.
Each category can be assigned to a single layer (visual group shown as a single row of data).
Note that overlapping categories shown in a single layer are possible, yet may not be visually sensible.
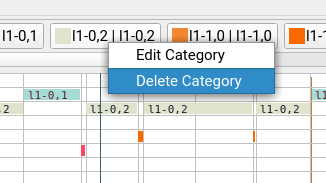
Right-clicking a category will yield a popup-menu for:
- category modification
- annotation deletion
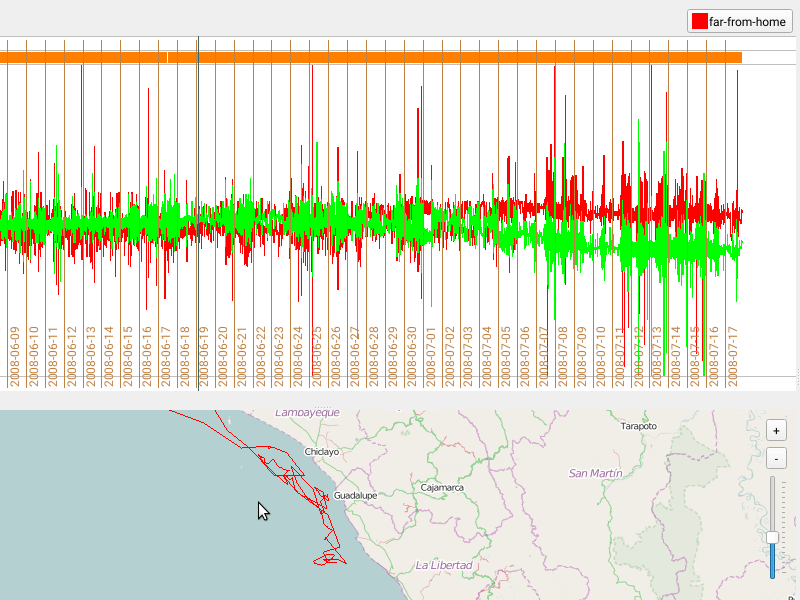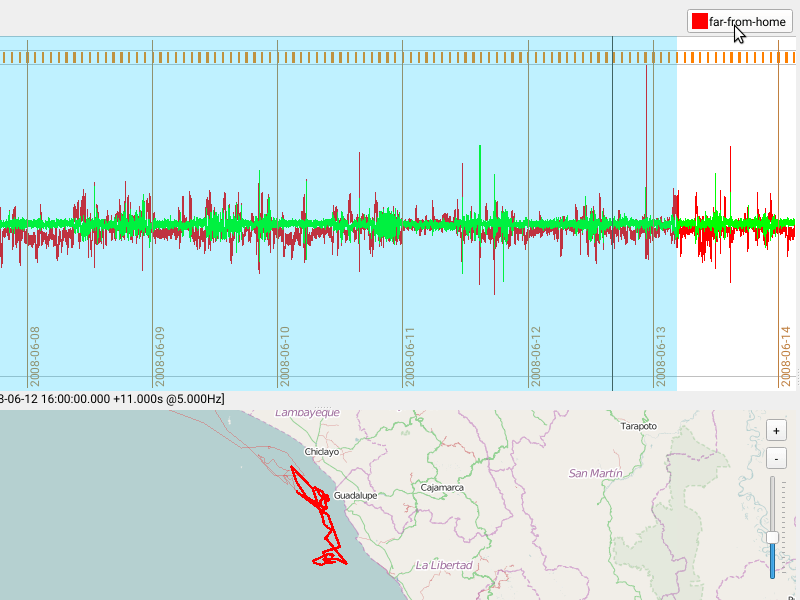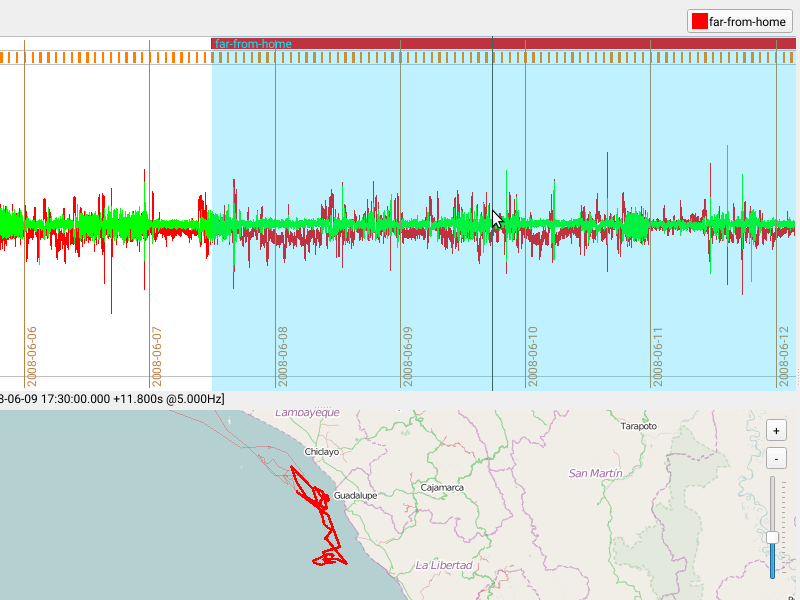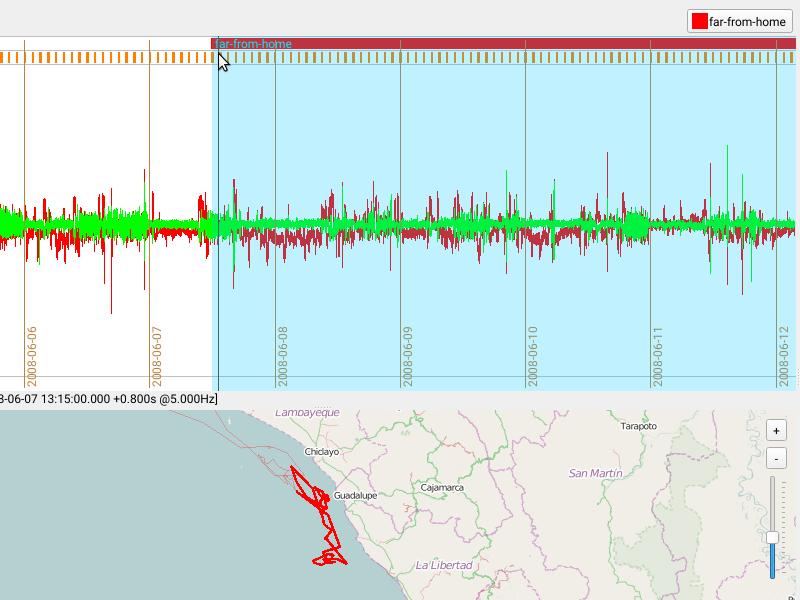
Saving Annotations and Removing a category
You can remove existing categories via right-clicking on the respective category and select
delete category. You are prompted that all annotations contained will be lost. There is currently
no undo for this, so make sure to use
File > Save Annotations
to save the current state.
Expert hint: the annotation resides in the respective
$USER/movebank_downloads/study_<num>folder asannotation2.csv(to ensure compatiblity with AccelerationViewer, this will likely change in future versions). Make sure to include this folder in your regular backup procedure