Acceleration annotation
Annotation of burst level data is increasingly important for a wide range of projects. Firetail provides you with a set of manual and machine learning assisted tools to rapidly annotate Movebank datasets with associated acc data.
Add new categories
To add a new category press Add Category above the acceleration window
Assign a name to the category
The category will show up above the acceleration window
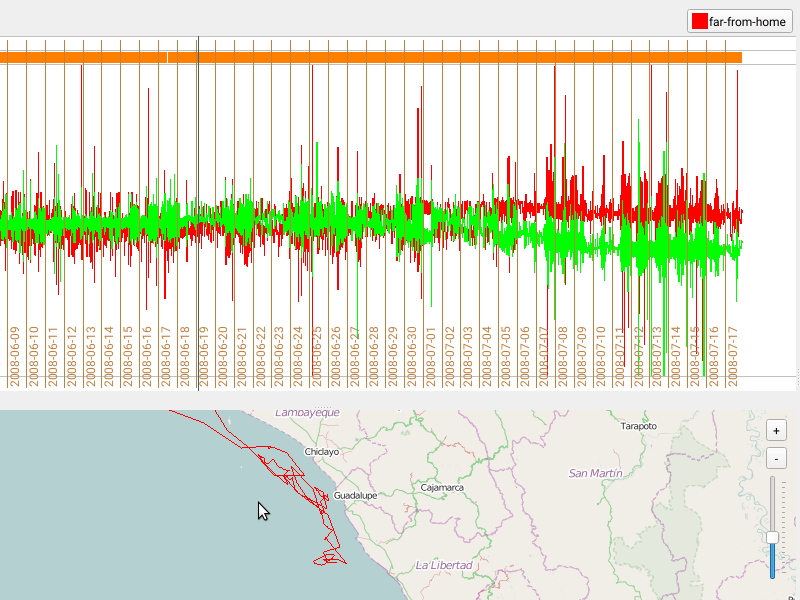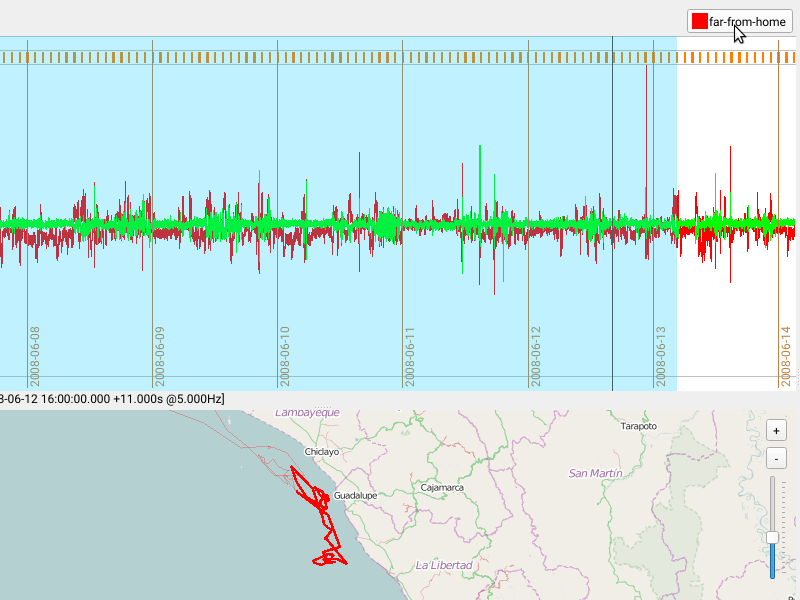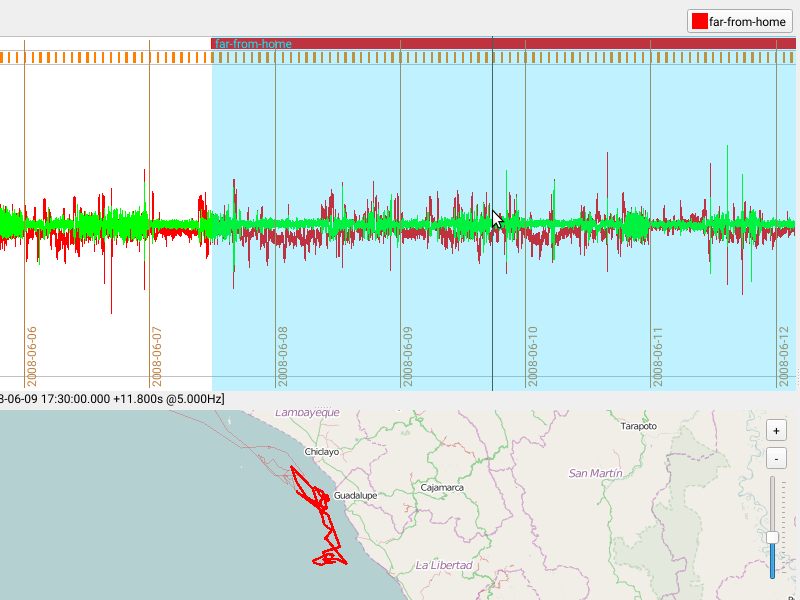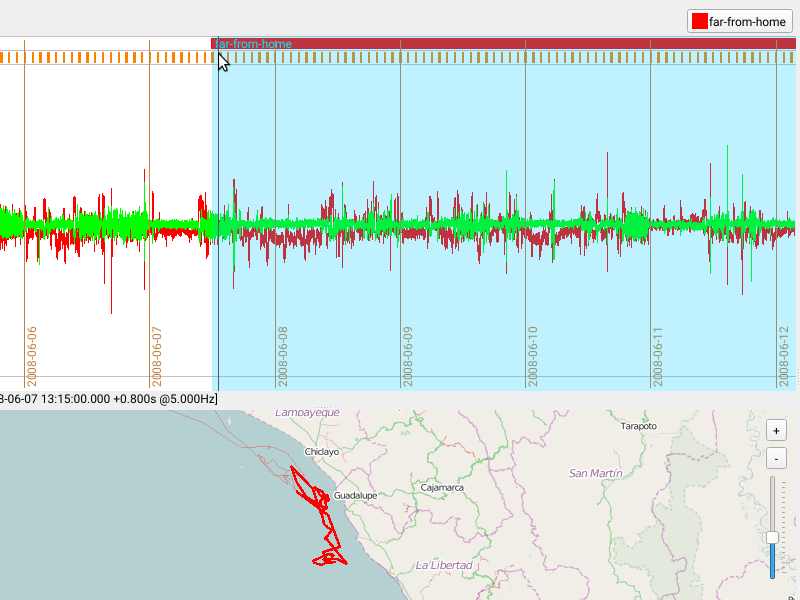
Assign a category to a region
Once you have defined categories, you can use the selection mechanism described here to define regions that you’d like to annotate with one of your categories.
- Select a region within the bursts or the map
- Press on the category you want to assign this region to
The newly assigned category will be shown in a row/layer above the acceleration data.
Each category can be assigned to a single layer (visual group shown as a single row of data).
Note that overlapping categories shown in a single layer are possible, yet may not be visually sensible.
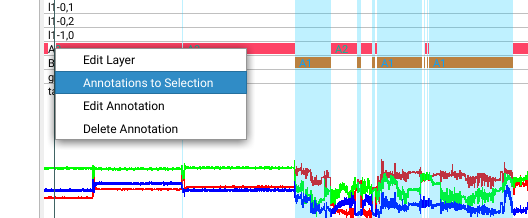
Right-clicking a category will yield a popup-menu for:
- annotation deletion
- layer modification
- category modification
FireSOM: Machine-learning assisted acceleration segmentation
IMPORTANT: Firetail’s annotation features are activated when loading data via
Download Movebank by ID/Tag/Deployment. Your annotation is saved locally (on your machine) along with the downloaded data.
When working with acceleration data manual annotation of large-scale data may be time-consuming or near-impossible.
Via Data > Calculate Acc Segmentation you can trigger Firetail’s automated segmentation algorithm FireSOM.
For each burst, Firetail calculates a set of features selected by the user. The burst is projected into feature space following a data normalisation. The built-in analysis will then assign each burst to a category. The model dimension determines the number of predicted categories.
Video Tutorial
Here you can find a video tutorial on FireSOM, see below for more details
Parameters
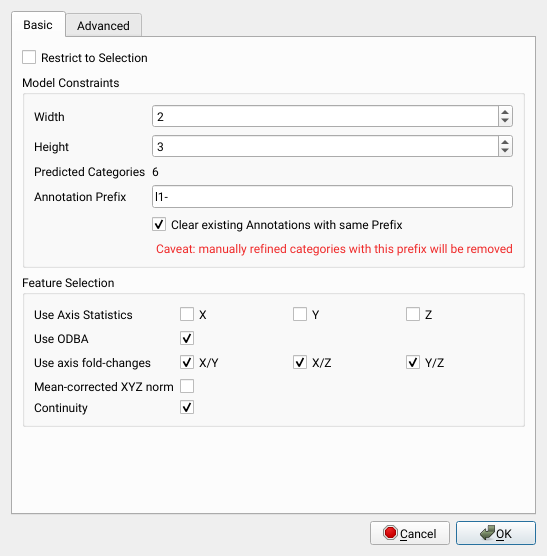
Restrict to Selection the algorithm will predict categories only for selected bursts.
NEW It is now possible to select regions by right-clicking a layer and choosing “Annotations to Selections”. This is extremely helpful to select regions that could not be segmented by a coarse model. For this selection a new model can then be trained.
Model Constraints
Width: the number of horizontal nodes, we suggest to use at least 2 depending on the complexity of data patterns
Height: the number of vertical nodes, we suggest to use at least 3 depending on the complexity of data patterns
Annotation Prefix: Each predicted category will be prefixed with this string
Clear existing Annotations with the same Prefix: Any previous annotation with this prefix will be removed. Consider renaming categories to avoid data loss
Feature Selection
Use Axis Statistics: add mean, median, and quantile statistics to the set of features, each axis Use ODBA: add overall dynamic body acceleration as a feature, all axes Use axis fold-changes: add statistics over log-2 fold-changes for selected pairs of axes mean-corrected norm: add the mean-corrected norm value for each burst continuity: add a measure of sum of changes
Click OK to train a model and see your results as new layers in the acceleration window.
Building a sensible model
While it is easy to train some model in Firetail you should not expect that your initial model will explain your data perfectly. Inspecting a predicted model is crucial. Luckily, Firetail provides you with a lot of context that makes it easier to interpret the predictions.
Overall, the model assumes that the similarity of two bursts, so similar patterns would lead to similar categories. Think of patterns in terms of activities like rest, running or feeding. The more categories you predict the more behavioural complexity can be detected. For increasingly many categories it may become necessary to join predictions via layers to group similar categories.
Start simple
Therefore, start by training a simple model with dimension 3 by 3 and few features. You can easily train a quick model as a preview or even experiment with how well a single feature works for discrimination of visual patterns or regions of known behaviour.
Increase complexity if required
An increasing number of features means there is more freedom to discriminate bursts. The result model will be harder to interpret though. Increase the model complexity or incrementally add features when two regions you deem dissimilar are placed in the same category.
Add local models where required
If the data features local specificities it could make sense to run the segmentation on a local selection. Make sure that at least a few hundred bursts are selected to avoid a poorly fitted model. By choosing a separate model prefix you can make sure to maintain both global and local predictions.
Assign, Rename and group
The machine-assigned group names cannot magically predict “running”, “feeding” or “flying”. Screen the predicted categories visually and in their best possible context to assign a category to a possibly preliminary behaviour. Repeated application of the segmentation, changes in parameters and successive joining of categories into layers of behavioral groups will lead to sensible annotations for complete datasets.